The inference method is crucial for NLP models in subword tokenization. Methods like BPE, WordPiece, and UnigramLM offer distinct mappings, but their performance differences must be better understood. Implementations like Huggingface Tokenizers often need to be clearer or limit inference choices, complicating compatibility with vocabulary learning algorithms. Whether a matching inference method is necessary or optimal for tokenizer vocabularies is uncertain.
Previous research focused on developing vocabulary construction algorithms such as BPE, WordPiece, and UnigramLM, exploring optimal vocabulary size and multilingual vocabularies. Some studies examined the effects of vocabularies on downstream performance, information theory, and cognitive plausibility. Limited work on inference methods investigated random effects on BPE merges and sophisticated search algorithms. A comprehensive study must be included comparing inference methods across various vocabularies and sizes.
The researchers from Ben-Gurion University of the Negev Beer Sheva And Massachusetts Institute of Technology have conducted a controlled experiment evaluating seven tokenizer inference methods across four algorithms and three vocabulary sizes. The experiment introduces an intrinsic evaluation suite combining measures from morphology, cognition, and information theory for English. They have shown that for the most commonly used tokenizers, greedy inference performs surprisingly well, while SaGe, a contextually informed tokenizer, outperforms others in morphological alignment.
In Greedy inference, they only consider and produce one token at each step and define three greedy approaches: Firstly, the “Longest prefix” method resembles the approach of selecting the longest token from the vocabulary that is a prefix of the word and iteratively segmenting the remaining text. Similarly, “Longest suffix” specifies the longest word suffix token and continues segmentation iteratively. Lastly, “Longest token” selects the longest token contained within the word, adds it to the segmentation, and continues segmenting the remaining characters. These strategies mirror the concept of greedy algorithms that make locally optimal choices at each step without considering the overall global solution.
The study’s thorough evaluation of inference methods across BPE, UnigramLM, WordPiece, and SaGe vocabularies has revealed variations in performance metrics. Merge rules-based inference methods often outperform default strategies, particularly notable in morphological alignment. Likelihood-based methods sometimes assign high likelihood values to frequently used tokens, affecting segmentation quality. SaGe demonstrates superior alignment to morphology. BPE and WordPiece excel in compression but lag in cognitive benchmarks. Likelihood and information-based vocabularies show consistent trends within their respective categories, highlighting the robustness of the benchmark.
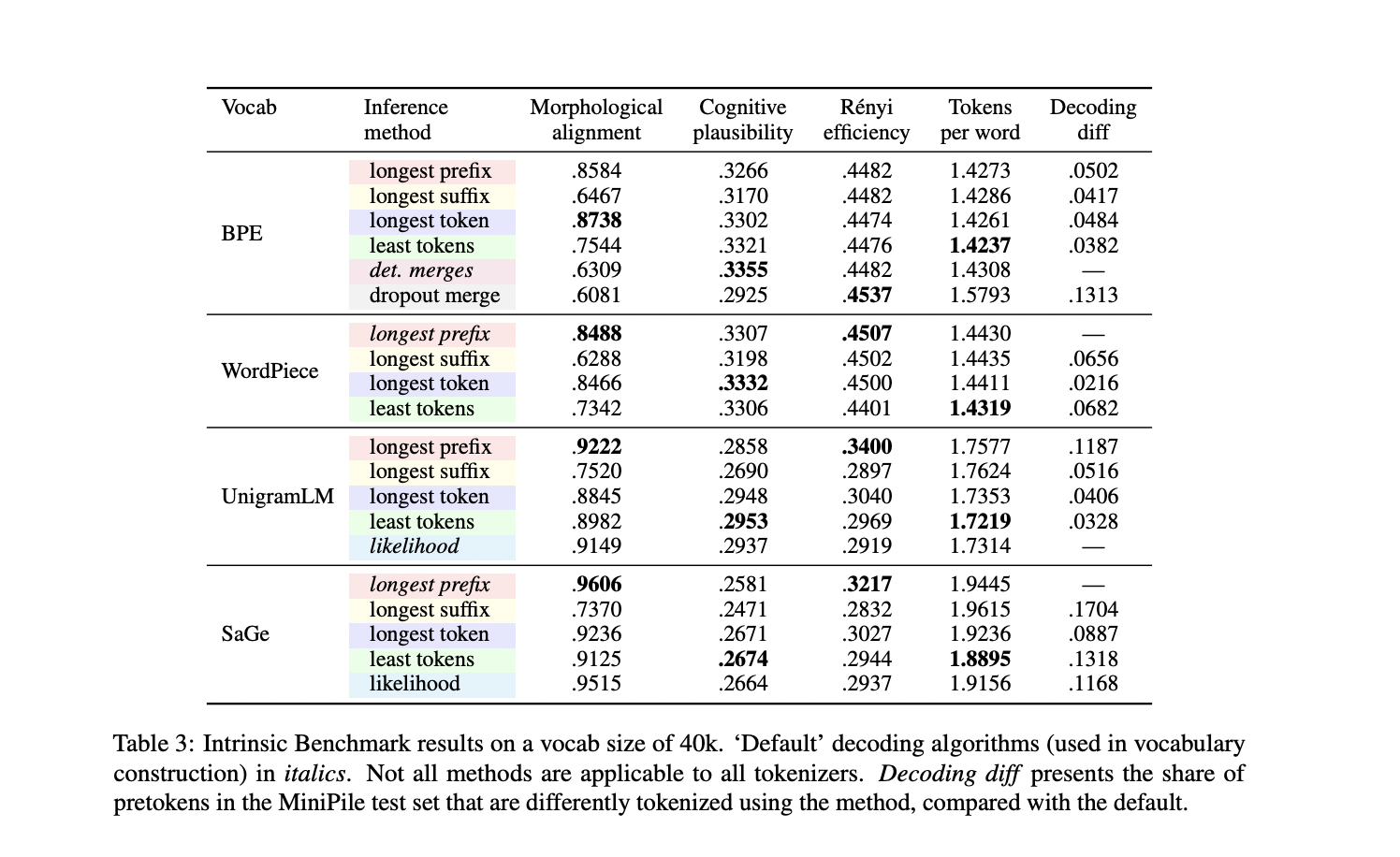
In conclusion, researchers from Ben-Gurion University of the Negev Beer Sheva And Massachusetts Institute of Technology have not only introduced an aggregated benchmark for evaluating subword tokenizers intrinsically but also emphasized the practical significance of their findings. Selecting suitable inference methods for specific vocabularies and tasks is crucial, and their computational efficiency can aid language model training by refining tokenization schemes and selecting inference methods. Greedy inference emerges as a favorable choice, particularly for morphologically driven tasks, even for tokenizers trained on different objectives.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
