Large language models (LLMs) trained on vast amounts of text data show remarkable abilities in diverse tasks via next-token prediction and fine-tuning. These tasks include marketing, reading comprehension, and medical analysis. While traditional benchmarks become obsolete due to LLM advancements, distinguishing between deep understanding and shallow memorization poses a challenge. Assessing LLMs’ true reasoning capabilities requires tests that evaluate their ability to generalize beyond training data, which is crucial for accurate assessments.
Often, this is at a level of coherence previously thought to be achievable only by human cognition (Gemini Team, OpenAI). They demonstrate significant applicability across chat interfaces and various other contexts. When evaluating the capabilities of a given AI system, the predominant traditional method is to measure how well an AI system performs at fixed benchmarks for specific tasks. However, it is also plausible that a significant portion of these successes on task benchmarks is due to superficial memorization of the task’s solutions and a shallow understanding of training-set patterns in general.
The researchers from MIT and others have presented their work in Study 1 and Study 2. In Study 1, researchers employ an ensemble approach, using twelve LLMs, to predict the outcomes of 31 binary questions. They compare these aggregated LLM predictions with 925 human forecasters from a three-month forecasting tournament. Results indicate the LLM crowd outperforms a no-information benchmark and matches the human crowd’s performance. Additionally, Study 2 explores enhancing LLM predictions by incorporating human cognitive output, focusing on GPT-4 and Claude 2 models.
In Study 1, researchers gathered data from twelve diverse LLMs, including GPT-4 and Claude 2. They compared LLM predictions on 31 binary questions with 925 human forecasters from a three-month tournament, finding statistical equivalence. In Study 2, researchers have exclusively focused on GPT-4 and Claude 2, utilizing a within-model design to collect pre- and post-intervention forecasts per question. They investigated LLMs’ updating behavior regarding human prediction estimates from a real-world forecasting tournament, employing longer prompts for guidance.
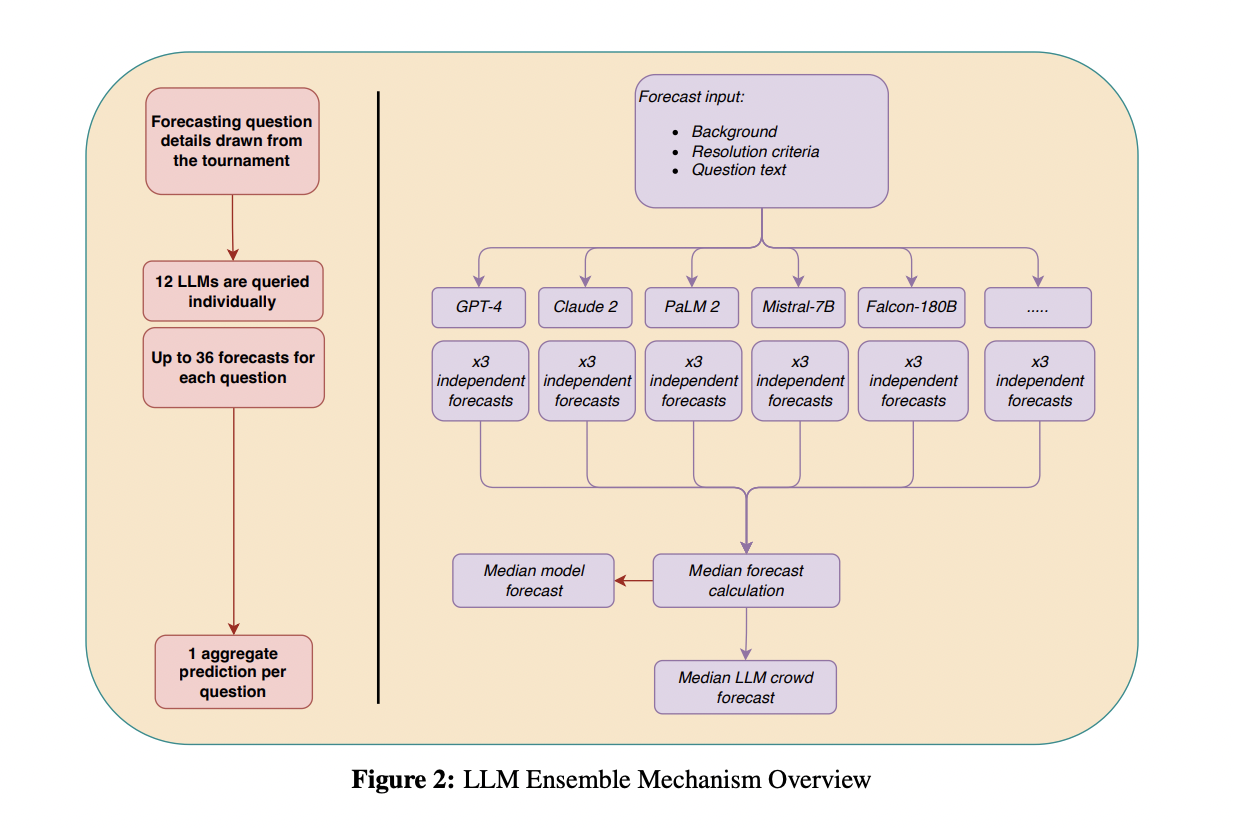
In study 1, they collected 1007 forecasts from 12 LLMs, observing predictions predominantly above the 50% midpoint. The mean forecast value of the LLM crowd significantly exceeded 50%, with 45% of questions resolving positively, indicating a bias towards positive outcomes. In Study 2,186 primary and updated forecasts from GPT-4 and Claude 2 were analyzed over 31 questions. Exposure to human crowd forecasts significantly improved model accuracy and narrowed prediction intervals, with adjustments correlating to the deviation from human benchmarks.
In conclusion, MIT and others have presented their study in LLM ensemble predictions. The study demonstrates that when LLMs harness collective intelligence, they can rival human crowd-based methods in probabilistic forecasting. While previous research showed LLMs underperforming in some contexts, combining simpler models in crowds may bridge the gap. This approach offers practical benefits for various real-world applications, potentially equipping decision-makers with accurate political, economic, and technological forecasts, paving the way for broader societal use of LLM predictions.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
