AI’s language understanding and visual perception intersection is a vibrant field pushing the limits of machine interpretation and interaction. A team of researchers from the Korea Advanced Institute of Science and Technology (KAIST) has developed MoAI, a noteworthy contribution to this field. MoAI heralds a new era in large language and vision models by ingeniously leveraging auxiliary visual information from specialized computer vision (CV) models. This approach enables a more nuanced comprehension of visual data, setting a new standard for interpreting complex scenes and bridging the gap between visual and textual understanding.
Traditionally, the challenge has been to create models that can seamlessly process and integrate disparate types of information to mimic human-like cognition. Despite the progress made by existing tools and methodologies, there remains a noticeable divide in the machine’s ability to grasp the intricate details that define our visual world. MoAI addresses this gap head-on by introducing a sophisticated framework synthesizing insights from external CV models, enriching the model’s capability to decipher and reason visual information in tandem with textual data.
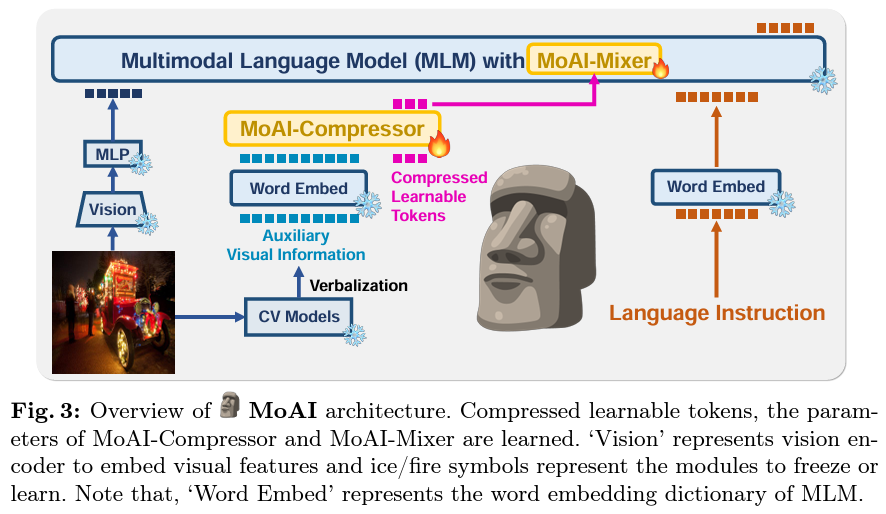
At its core, MoAI’s architecture is distinguished by two innovative modules: the MoAI-Compressor and the MoAI-Mixer. The former processes and condenses the outputs from external CV models, transforming them into a format that can be efficiently utilized alongside visual and language features. The latter blends these diverse inputs, facilitating a harmonious integration that empowers the model to tackle complex visual language tasks with unprecedented accuracy.
The efficacy of MoAI is vividly illustrated in its performance across various benchmark tests. MoAI surpasses existing open-source models and outperforms proprietary counterparts in zero-shot visual language tasks, showcasing its exceptional ability in real-world scene understanding. Specifically, MoAI achieves remarkable scores in benchmarks such as Q-Bench and MM-Bench, with accuracy rates of 70.2% and 83.5%, respectively. In the challenging TextVQA and POPE datasets, it secures accuracy rates of 67.8% and an astounding 87.1%. These figures highlight MoAI’s superiority in deciphering visual content and underscore its potential to revolutionize the field.
What sets MoAI apart is its performance and the underlying methodology, which eschews the need for extensive curation of visual instruction datasets or the enlargement of model sizes. MoAI demonstrates that integrating detailed visual insights can significantly enhance the model’s comprehension and interaction capabilities by focusing on real-world scene understanding and leveraging the rich history of external CV models.
The success of MoAI has profound implications for the future of artificial intelligence. This model represents a significant step toward achieving a more integrated and nuanced form of AI that can interpret the world similarly to human cognition. The success of MoAI suggests that the way forward for large language and vision models is to merge various intelligence sources, which opens new research and development avenues in AI.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 38k+ ML SubReddit
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
