Large language models (LLMs) such as GPT-4 and Llama are at the forefront of natural language processing, enabling various applications from automated chatbots to advanced text analysis. However, the deployment of these models is hindered by high costs and the necessity to fine-tune numerous system settings to achieve optimal performance.
The deployment of LLMs involves a complex selection process among various system configurations, such as model parallelization, batching strategies, and scheduling policies. Traditionally, this optimization requires extensive and costly experimentation. For instance, finding the most efficient deployment configuration for the LLaMA2-70B model could consume over 42,000 GPU hours, amounting to approximately $218,000 in expenses.
A group of researchers from Georgia Institute of Technology, Microsoft Research India, has developed Vidur, a simulation framework specifically designed for LLM inference. Vidur employs a combination of experimental data and predictive modeling to simulate the performance of LLMs under different configurations. This simulation allows for assessing key performance metrics like latency and throughput without costly and time-consuming physical trials.
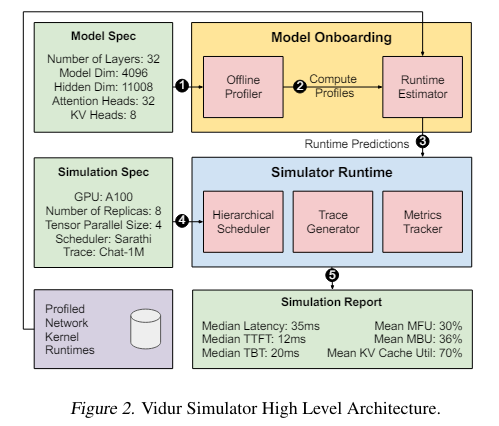
A pivotal component of Vidur is its configuration search tool, Vidur-Search, which automates the exploration of deployment configurations. This tool efficiently pinpoints the most cost-effective settings that meet predefined performance criteria. For example, Vidur-Search determined an optimal setup for the LLaMA2-70B model on a CPU platform in just one hour, a task typically requiring extensive GPU resources.
Vidur’s capabilities extend to evaluating various LLMs across different hardware setups and cluster configurations, maintaining a prediction accuracy rate of less than 9% error for inference latency. The framework also introduces Vidur-Bench, a benchmark suite that facilitates comprehensive performance evaluations using diverse workload patterns and system configurations.
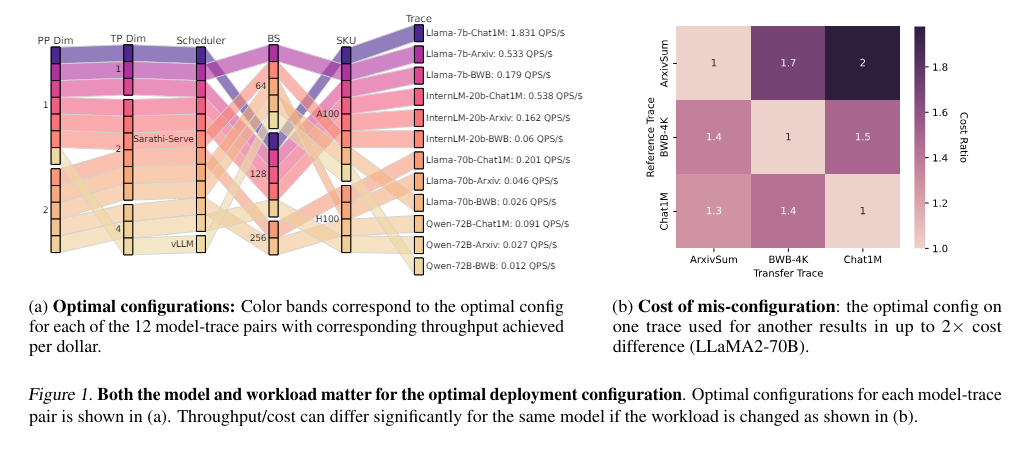
In practice, Vidur has demonstrated substantial cost reductions in LLM deployment. Using Vidur-Search in simulation environments has dramatically cut down potential costs. What would have amounted to over $200,000 in real-world expenses can be simulated for a fraction of the cost. This efficiency is achieved without sacrificing the accuracy or relevance of the results, ensuring that performance optimizations are both practical and effective.

In conclusion, the Vidur simulation framework addresses the high costs and complexity of deploying large language models by introducing an innovative method combining experimental profiling with predictive modeling. This approach enables accurate simulation of LLM performance across various configurations, significantly reducing the need for expensive and time-consuming physical testing. Vidur’s efficacy is underscored by its ability to fine-tune deployment configurations, achieving less than 9% error in latency predictions and drastically cutting down on GPU hours and related costs, making it a pivotal tool for streamlining LLM deployment in practical, cost-effective ways.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.
