Large language models (LLMs) are central to processing vast amounts of data quickly and accurately. They depend critically on the quality of instruction tuning to enhance their reasoning capabilities. Instruction tuning is essential as it prepares LLMs to solve new, unseen problems effectively by applying learned knowledge in structured scenarios.
Securing high-quality, scalable instruction data remains a principal challenge in the domain. Earlier methods, which rely heavily on human input or sophisticated algorithms for distilling complex datasets into usable training materials, are often constrained by high costs, limited scalability, and potential biases. These drawbacks necessitate a more efficient method for acquiring the massive, diverse datasets needed for effective LLM training.
Researchers from Carnegie Mellon University and the University of Waterloo have developed an innovative approach known as Web-Instruct, which bypasses traditional limitations by sourcing instruction data directly from the Internet. This method exploits the rich, diverse online content, converting it into a valuable resource for tuning LLMs. The process involves selecting relevant documents from a broad web corpus, extracting potential instruction-response pairs, and refining these pairs to ensure high quality and relevance for LLM tasks.
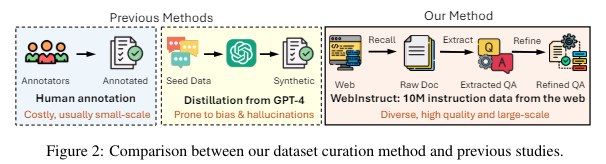
They also build the MAmmoTH2 model, tuned using the Web-Instruct dataset, showcasing this method’s effectiveness. The dataset, comprising 10 million instruction-response pairs, is gathered without the significant costs associated with human data curation or the biases from model distillation methods. This large and diverse dataset has propelled MAmmoTH2 to achieve remarkable performance improvements. For instance, MAmmoTH2 demonstrated a surge in accuracy from 11% to 34% on complex reasoning tasks, such as mathematical problem-solving and scientific reasoning, without specific domain training.
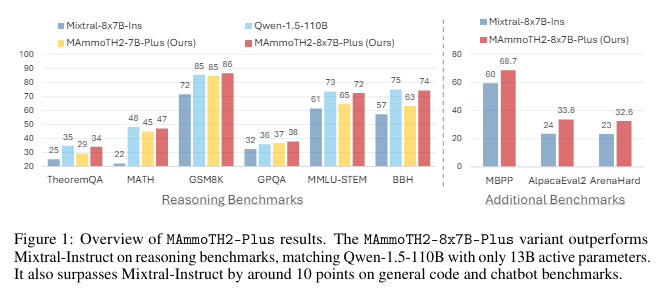
MAmmoTH2-Plus is an enhanced model version that integrates additional public instruction datasets for broader training. This model variant has been shown to outperform base models on standard reasoning consistently benchmarks like TheoremQA and GSM8K, with improvements in performance of up to 23% compared to previous benchmarks. MAmmoTH2-Plus also excelled in general tasks, indicating its strong generalization capabilities across a spectrum of complex reasoning and conversational benchmarks.

In conclusion, the Web-Instruct method and the subsequent development of the MAmmoTH2 and MAmmoTH2-Plus models mark significant advances in instruction tuning for LLMs. This approach offers a scalable, cost-effective alternative to traditional data collection and processing methods by leveraging the extensive and diverse online instructional content. The success of models tuned with this dataset underscores the potential of web-mined instruction data to dramatically enhance the reasoning abilities of LLMs, broadening their application scope and setting new benchmarks for data quality and model performance in AI.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.
