Recently, Large Language Models (LLMs) have played a crucial role in the field of natural language understanding, showcasing remarkable capabilities in generalizing across a wide range of tasks, including zero-shot and few-shot scenarios. Vision Language Models (VLMs), exemplified by OpenAI’s GPT-4 in 2023, have demonstrated substantial progress in addressing open-ended visual question-answering (VQA) tasks, which require a model to answer a question about an image or a set of images. These advancements have been achieved by integrating LLMs with visual comprehension abilities.
Various methods have been proposed to leverage LLMs for vision-related tasks, including direct alignment with a visual encoder’s patch feature and the extraction of image information through a fixed number of query embeddings.
However, despite their significant capabilities in image-based human-agent interactions, these models encounter challenges when it comes to interpreting text within images. Text-containing images are prevalent in everyday life, and the ability to comprehend such content is crucial for human visual perception. Previous research has employed an abstraction module with queried embeddings, but this approach limited their capacity to capture textual details within images.
In the study outlined in this article, the researchers introduce BLIVA (InstructBLIP with Visual Assistant), a multimodal LLM strategically engineered to integrate two key components: learned query embeddings closely aligned with the LLM itself and image-encoded patch embeddings, which contain more extensive image-related data. An overview of the proposed approach is presented in the figure below.
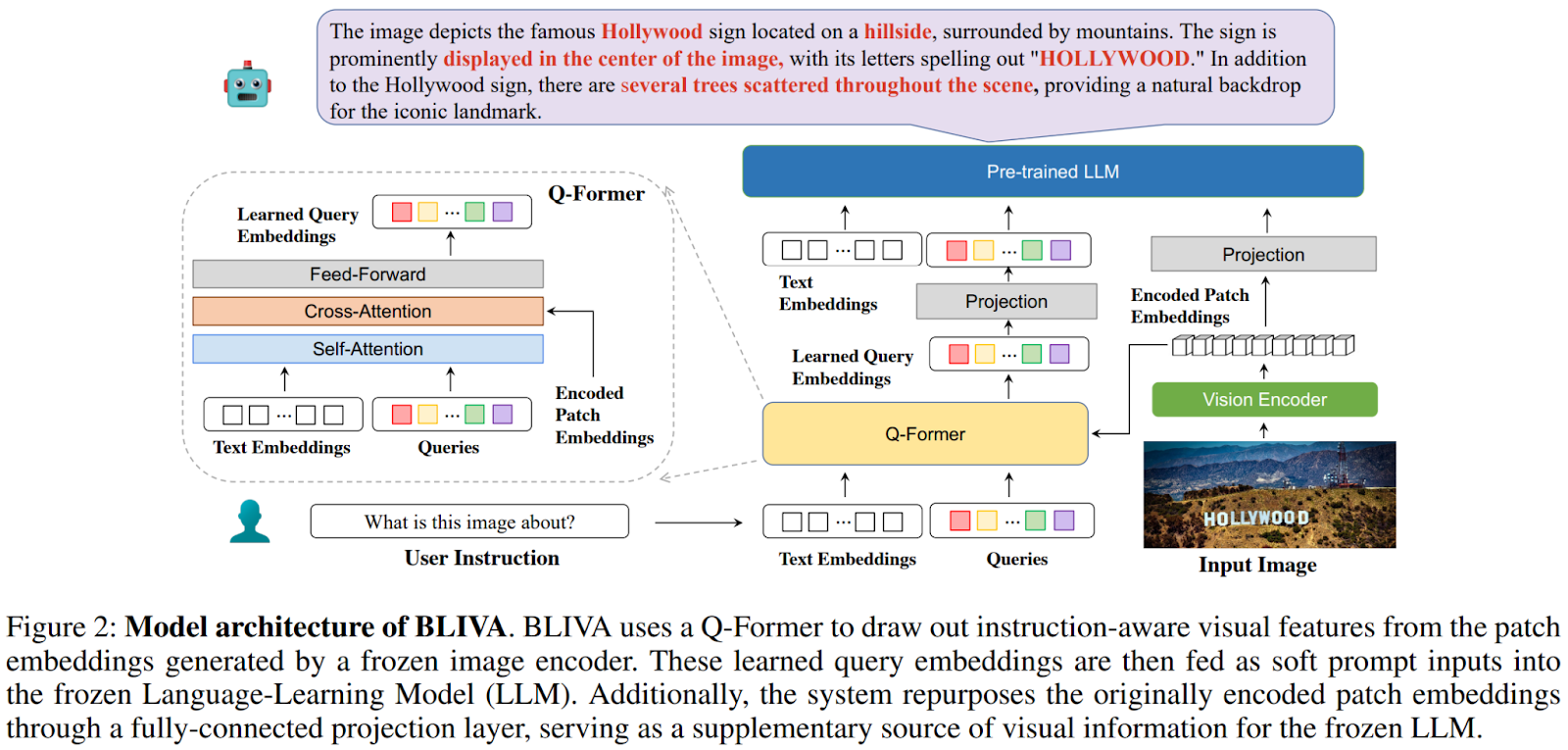
This technique overcomes the constraints typically associated with the provision of image information to language models, ultimately leading to enhanced text-image visual perception and understanding. The model is initialized using a pre-trained InstructBLIP and an encoded patch projection layer trained from scratch. A two-stage training paradigm is followed. The initial stage involves pre-training the patch embeddings projection layer and fine-tuning both the Q-former and the patch embeddings projection layer using instruction tuning data. Throughout this phase, both the image encoder and LLM remain in a frozen state, based on two key findings from experiments: first, unfreezing the vision encoder leads to catastrophic forgetting of prior knowledge, and second, simultaneous training of the LLM did not yield improvement but introduced significant training complexity.
Two sample scenarios presented by the authors are reported here, showcasing the impact of BLIVA in addressing VQA tasks related to “Detailed caption” and “small caption + VQA.”

This was the summary of BLIVA, a novel AI LLM multimodal framework that combines textual and visual-encoded patch embeddings to address VQA tasks. If you are interested and want to learn more about it, please feel free to refer to the links cited below.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
