Tokenization is essential in computational linguistics, particularly in the training and functionality of large language models (LLMs). This process involves dissecting text into manageable pieces or tokens, which is foundational for model training and operations. While effective tokenization can significantly enhance a model’s performance, issues arise when tokens within the model’s vocabulary are underrepresented or absent in the training datasets, leading to what researchers term ‘glitch tokens.’ When encountered in new input data, these tokens can destabilize a model and produce unpredictable outputs.
A prevalent issue in LLMs is the misalignment between tokenizer training and model training. Often, tokenizers are trained separately using distinct datasets, which can differ significantly from the data used to train the model. This disjoint can lead to some of the vocabulary glitch tokens being under-trained. The infamous “_SolidGoldMagikarp” token is a notorious glitch token that can induce unwanted model behaviors, such as hallucinations or producing nonsensical outputs.
Conventional methods for identifying under-trained tokens typically involve manual checks of the tokenizer’s behavior, examining how tokens are encoded and decoded, or analyzing their frequency in the training data. However, these methods are not scalable for the increasingly large and complex LLMs being developed today.
Researchers from Cohere introduce a novel approach that utilizes the model’s embedding weights to automate and scale the detection of under-trained tokens. The researchers developed a method to analyze these weights to spot anomalies indicative of insufficient training. By assessing the embedding matrix of a model, the research identifies tokens whose embedding weights deviate significantly from those of well-represented tokens. This method provides a systematic way to pinpoint glitch tokens by calculating the variance and distribution of embedding weights and comparing them against a normative model of adequately trained tokens.
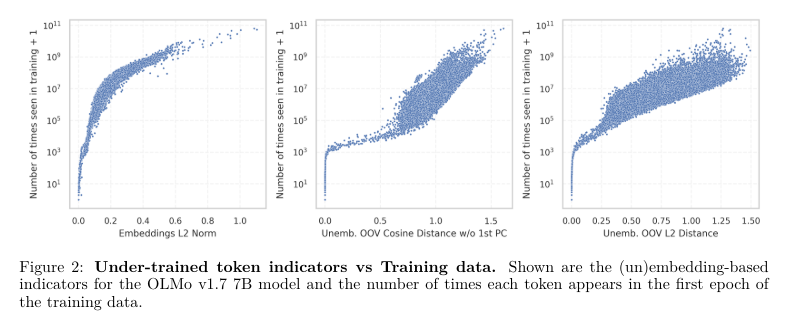
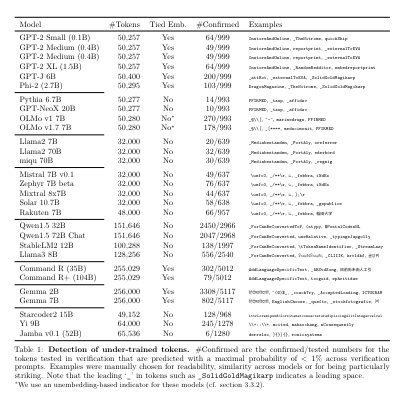
The study demonstrated the effectiveness of this new method by applying it to several well-known models, including variations of Google’s BERT and OpenAI’s GPT series. The analysis identified a substantial percentage of the tokenizer’s vocabulary, up to 10% in some cases, as under-trained. These tokens were often specialized or infrequently used words, which exhibited the most significant discrepancies in embedding weight patterns.
This research has significant implications for the development and maintenance of LLMs. By employing automated techniques to detect and rectify under-trained tokens, developers can enhance the accuracy and robustness of language models. This advancement is crucial as LLMs are increasingly used in various applications, from automated writing aids to sophisticated conversational agents.

In conclusion, this research highlights a critical vulnerability in LLM training and presents a scalable solution to mitigate this issue. Implementing automated methods for detecting under-trained tokens allows for more robust training processes, ensuring that all tokens in a model’s vocabulary are adequately prepared to handle real-world applications. This research improves the efficacy and reliability of language models, paving the way for more reliable and effective natural language processing tools.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.
